1
Target
真正去做任務的 AI。它讀技能文件,就像學生照筆記解題。
SkillOpt 不是直接改 AI 大腦裡的參數,而是讓 AI 反覆做題、看錯題、修改一份 Markdown 技能文件,最後留下分數真的變好的版本。
Target AI
做題 AI
Optimizer AI
批改 AI
Gate
只有變好才收進講義
核心想法
平常我們會寫 prompt 告訴 AI 怎麼做事。SkillOpt 把這份 prompt 升級成「skill document」:一份可以被測驗、被修改、被驗證的 Markdown 文件。
中學生比喻:你準備自然科考試,老師不會每天重新改造你的大腦,而是讓你寫題目、看錯題、修筆記。下次遇到同類題目,你靠更好的筆記做得更穩。
SkillOpt 做的事:讓 AI agent 用目前的技能文件去完成任務,另一個 optimizer AI 根據成功和失敗紀錄提出修改。修改後先考驗證題,分數沒有變好就退回。
真正去做任務的 AI。它讀技能文件,就像學生照筆記解題。
負責批改軌跡、找出錯誤模式,提出「哪幾句講義要改」。
像小考門檻:新講義必須在 validation 題目上更好,才被接受。
Training loop
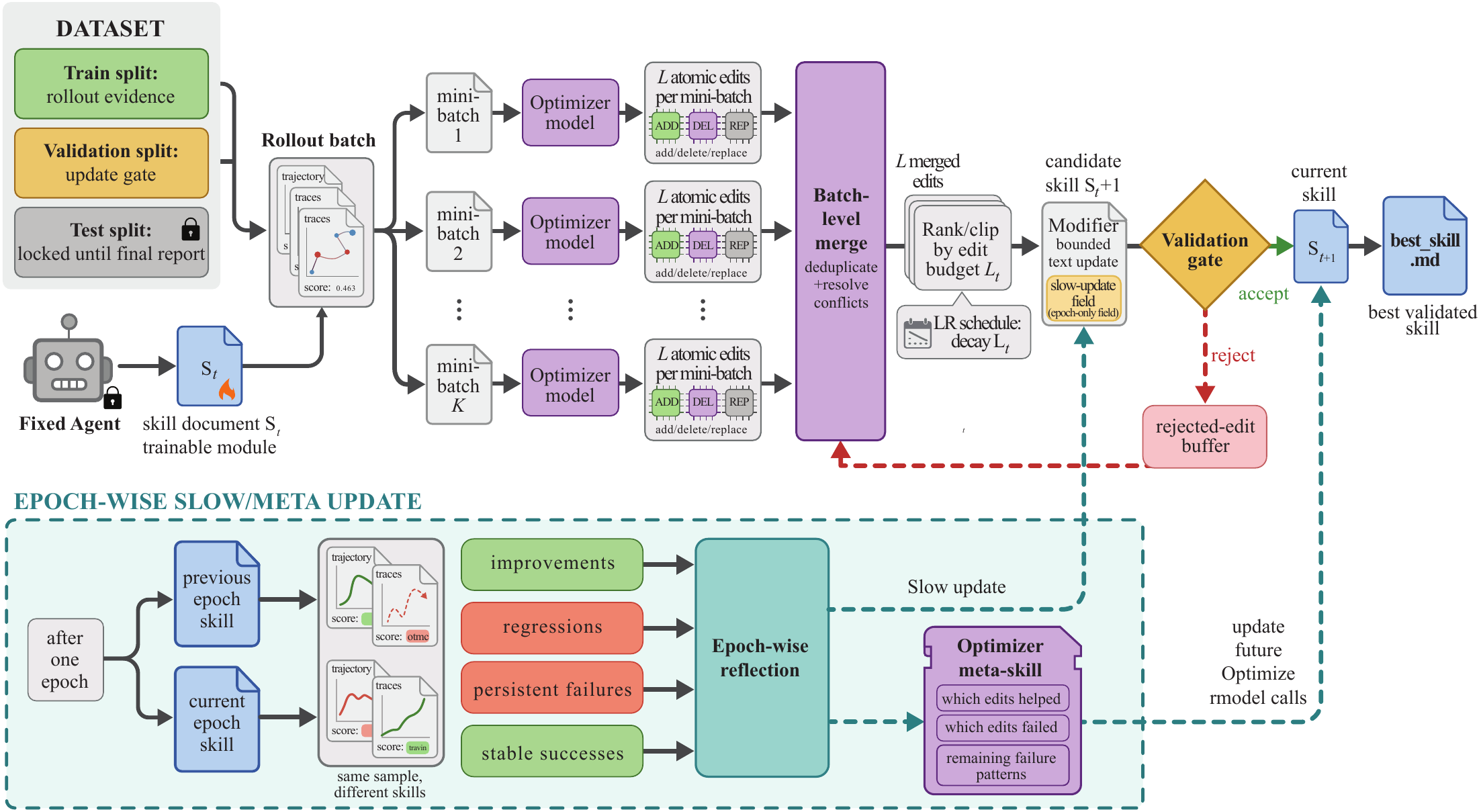
SkillOpt 的訓練迴圈有六步。原始碼裡的 trainer 也把它印成 1/6 到 6/6:Rollout、Reflect、Aggregate、Select、Update、Evaluate。
AI 用目前講義去做一批題目,留下過程與分數。
教練 AI 看成功與失敗,寫出改講義的 patch。
把相似建議合併,避免同一件事改三次。
只選最重要的幾個修改,learning rate 就是修改上限。
把選中的新增、替換、刪除規則套到 Markdown 講義。
用驗證題重考。更好才收下;沒有更好就拒絕。
像深度學習,但不改權重
SkillOpt 的文件說法很直接:它把自然語言技能文件當成要優化的東西,流程長得像訓練神經網路,但不需要更新模型權重。
Skill document
它不是神秘檔案,而是人看得懂的 Markdown。可以寫一般策略、常見模式、邊界情況與輸出格式。
# 解題策略 ## 一般方法 - 先把問題拆成小步驟 - 每一步都檢查證據 ## 常見錯誤 - 如果題目問年份,不要只回答人物 - 如果資料不足,要明確說不知道 ## 輸出格式 - 先給短答案 - 再列出理由與來源
Validation gate
因為 AI 可能提出看起來合理、其實讓成績變差的規則。SkillOpt 的 gate 很像老師說:「新版筆記要在驗證考卷分數更高,才可以取代舊版。」
舊講義
72 目前 validation 分數新講義
78 更高,接受並可能成為 new best原 repo 圖片
下面兩張圖來自 SkillOpt repo 的專案素材。第一張是整體 pipeline,第二張是 epoch 趨勢;這裡保留原圖,旁邊的文字則用中學生版本重新解釋。
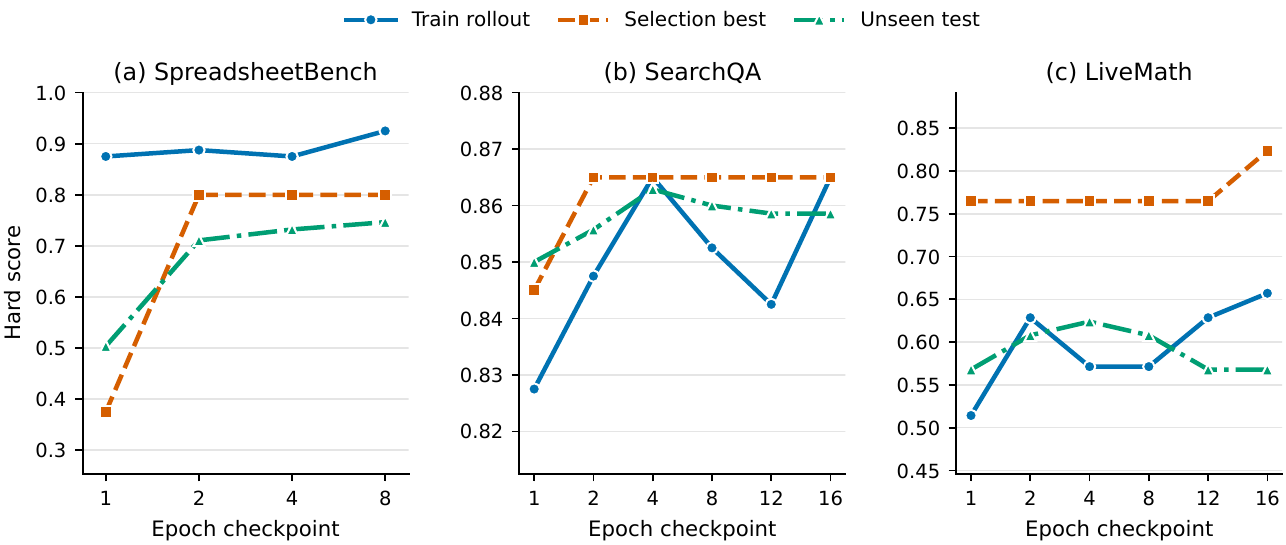
拆開看
微調通常是改模型權重;SkillOpt 改的是技能文件。這讓它比較像「把一份工作手冊改到更好」,而不是「把整個模型重新訓練」。
README 說資料會分成 train、val、test。train 用來練習與找錯,validation 用來 gate,test 則是最後保留檢查。
每次訓練會留下 history、runtime state、每一步技能快照,以及最好的 `best_skill.md`。這份檔案可以再拿去 eval only 評測。
快速小測驗
選一個答案。這不是考倒你,而是模擬 SkillOpt 的精神:做題、得到回饋、修正理解。
SkillOpt 主要改進的是什麼?
Sources
專案 README 連到 arXiv 論文:SkillOpt: Executive Strategy for Self-Evolving Agent Skills。
arXiv:2605.23904